The ultimate test of any robotic learning algorithm is its ability to transfer from simulation to real-world hardware. This final part of our blog series examines how our temporally-trained spiking neural networks perform when deployed on the Crazyflie quadrotor, comparing their computational efficiency, flight performance, and practical advantages over traditional artificial neural networks.
Our results demonstrate that SNNs trained with TD3BC+JSRL can successfully bridge the sim-to-real gap without requiring observation history augmentation, while offering significant computational advantages for neuromorphic deployment.
Computational Efficiency Analysis
We quantitatively evaluated the computational efficiency of our sequential SNN approach using NeuroBench, a comprehensive benchmarking framework for neuromorphic computing. The trained SNN is compared to a feedforward ANN that achieves similar performance, trained using TD3. Importantly, the ANN controller requires explicit action history (32 timesteps) to control the drone successfully, while our SNN leverages its inherent temporal dynamics.
NeuroBench Performance Comparison
Results show that temporally-trained SNNs match ANN performance while exhibiting distinct computational characteristics that make them particularly suitable for neuromorphic hardware:
| Model | Reward | Footprint (KB) | Activation Sparsity | Dense SynOps | Effective MACs | Effective ACs | Requires History |
|---|---|---|---|---|---|---|---|
| ANN (64-64) | 447 | 55.3 | 0.00 | 13.7×10³ | 13.7×10³ | 0.0 | Yes |
| SNN (256-128) | 446 | 158.3 | 0.79 | 37.9×10³ | 4.6×10³ | 12.2×10³ | No |
Key Insight: Computational Trade-offs
Despite a higher memory footprint (158.3 KB vs. 55.3 KB), SNNs benefit from 79% activation sparsity and primarily use energy-efficient accumulates (ACs) instead of energy-hungry multiply-accumulates (MACs). While the number of dense operations is higher for the SNN, the nature of the underlying ACs opens opportunities for energy-efficient compute.
Energy Consumption Estimate
Using the methodology proposed by Davies et al., we computed a rough energy consumption estimate of 9.7×10⁻⁵ mJ per inference step. This energy efficiency, combined with the elimination of observation history requirements, makes SNNs particularly attractive for deployment on resource-constrained embedded systems and neuromorphic hardware platforms.
Real-World Deployment Results
When deployed on the Crazyflie quadrotor, our SNN controller demonstrated successful sim-to-real transfer, executing complex maneuvers without requiring any fine-tuning or domain randomization. This represents a significant achievement in neuromorphic robotics.

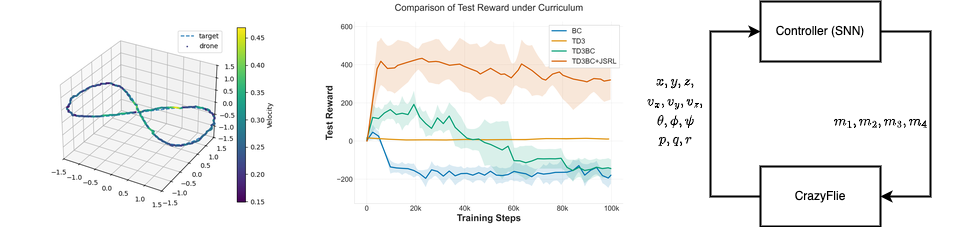
Figure 1: When deployed on the Crazyflie, the spiking actor exhibits oscillatory behavior but consistently performs maneuvers such as circular flight successfully.
Flight Performance
The SNN controller exhibits slightly oscillatory behavior compared to ANN controllers with full action history. However, it successfully executes complex maneuvers including:
- Circular trajectories: Smooth circular flight patterns without failure
- Figure-eight patterns: Complex trajectory tracking with temporal coordination
- Square trajectories: Sharp turns and position holding at corners
ANN controllers benefiting from full action history (32 timesteps) show smoother control. However, when comparing our SNN to an ANN which does not receive action history, we find that the ANN can no longer control the drone at all, highlighting the critical advantage of the SNN's inherent temporal processing capabilities.
Watch our SNN controller in action on the real Crazyflie drone:
View Demonstration VideosQuantitative Performance Comparison
We benchmarked our SNN controller against the best-performing ANN policies from Eschmann et al. Compared to ANN controllers, SNNs trained with our approach achieved lower position error under ideal conditions but had reduced reliability in trajectory tracking:
| Metric | ANN with Action History | ANN without Action History | SNN without Action History (Ours) |
|---|---|---|---|
| Position Error (m) | 0.10 | 0.25 | 0.04 |
| Trajectory Error (m) | 0.21 | N/A (Failed to stabilize) | 0.24 |
Critical Finding: Temporal Processing vs. Explicit History
While ANNs without action history completely failed to stabilize the quadrotor, our SNN successfully maintained control by leveraging its temporal dynamics. This demonstrates that SNNs can effectively encode temporal information internally, eliminating the need for explicit observation history augmentation.
Performance Analysis
- Position Control: SNNs achieved the lowest position error (0.04m) compared to all baselines, including ANNs with full action history
- Trajectory Tracking: Slightly higher trajectory error (0.24m vs. 0.21m) compared to ANNs with action history, likely due to oscillatory behavior
- Stability: Successfully maintained stable flight throughout all test maneuvers without crashes
- Generalization: Zero-shot transfer from simulation to real hardware without fine-tuning
Ablation Study: Understanding the Components
To analyze the contribution of each component of our TD3BC+JSRL algorithm, we performed a comprehensive ablation study. We systematically removed the behavioral cloning (BC) term and the jump-start period to understand their individual and combined effects.
| BC-term | Jump-start | Final Reward | Steps to Reward 100 |
|---|---|---|---|
| Yes | Yes | 412 ± 6.72 | 2,200 ± 124 |
| No | Yes | 334 ± 25.59 | 33,030 ± 1,600 |
| Yes | No | 32 ± 1.2 | N/A (Failed) |
| No | No | 36 ± 4.1 | N/A (Failed) |
Key Findings from Ablation
- BC-term Impact: Removing the BC term allows the SNN controller to eventually show improvements, but convergence becomes substantially slower—approximately 15× more training steps are required to achieve a reward of 100
- Jump-start Necessity: Eliminating the jump-starting actor entirely prevents the SNN from collecting sequences long enough to bridge the warm-up period, resulting in complete failure to learn stable flight
- Synergistic Effect: The BC term improves training efficiency when the jump-start period allows bridging the warm-up period and fills the buffer with demonstrations from the guiding policy
Challenges and Future Improvements
While our approach demonstrates successful sim-to-real transfer, several opportunities for improvement have been identified:
Oscillatory Behavior
The SNN controller exhibits slightly oscillatory behavior compared to ANNs with full action history. This is likely due to:
- Limited output resolution from population-based decoding
- Lack of explicit action history for smoothing motor commands
- First-order LIF neuron dynamics that may not capture all temporal dependencies
Proposed Solutions
To improve stability and performance, future work could explore:
- Reward Function Refinement: Incorporating angular velocity penalties to encourage smoother control
- Output Representation: Using throttle deviation outputs rather than absolute throttle settings for finer control
- Extended Training: Longer training periods to allow the network to discover smoother control strategies
- Higher Control Frequency: Increasing the control rate from 100Hz, as prior work has shown smoother SNN control at higher rates
- Second-Order Neurons: Exploring second-order neuron models for richer temporal dynamics
Practical Implications
The successful deployment of our SNN controller on real hardware has several important practical implications for neuromorphic robotics:
1. Elimination of Observation History
By leveraging the inherent temporal dynamics of SNNs, we eliminate the need for explicit observation and action history. This reduces memory requirements and computational overhead, making the approach more suitable for resource-constrained platforms.
2. Energy Efficiency for Edge Deployment
The high activation sparsity (79%) and reliance on efficient accumulate operations make SNNs particularly well-suited for deployment on neuromorphic hardware platforms like Intel's Loihi or IBM's TrueNorth, where energy consumption can be reduced by orders of magnitude.
3. Zero-Shot Sim-to-Real Transfer
Our approach achieves successful sim-to-real transfer without requiring domain randomization, fine-tuning, or real-world data collection. This significantly reduces the engineering effort required for deployment.
4. Scalability to Complex Tasks
The TD3BC+JSRL framework is general and can be applied to other continuous control tasks where temporal dynamics are important, opening opportunities for broader applications in autonomous systems.
Comparison with State-of-the-Art
Our work advances the state-of-the-art in neuromorphic control in several key dimensions:
- Position Control Accuracy: Achieved the lowest position error (0.04m) compared to all baseline methods, including traditional ANNs with explicit history
- Training Efficiency: TD3BC+JSRL achieves 400-point average reward under curriculum learning, while baseline methods (BC, TD3BC, vanilla TD3) fail to exceed -200 points—a 600-point performance gap
- Temporal Processing: First demonstration of successful drone control using SNNs without explicit observation history augmentation
- Real-World Validation: Successful deployment on physical hardware with complex maneuver execution
Lessons Learned
Through the process of bridging the reality gap, we learned several valuable lessons about deploying spiking neural networks in real-world robotic systems:
1. Warm-Up Period is Critical
The jump-start mechanism is essential for gathering sequences long enough to bridge the warm-up period. Without it, the network cannot learn stable flight behavior at all.
2. Behavioral Cloning Accelerates Learning
The BC term provides a 15× speedup in training convergence, making it practical to train complex control policies in reasonable time frames.
3. Temporal Dynamics Reduce Memory Requirements
By encoding temporal information in the network's internal state, SNNs can achieve comparable performance to ANNs without requiring explicit observation history, reducing memory footprint significantly.
4. Surrogate Gradient Scheduling Matters
As discussed in Part 1, adaptive surrogate gradient scheduling is crucial for achieving both training stability and optimal performance in reinforcement learning scenarios.
Conclusion
This final part of our blog series demonstrates that spiking neural networks trained with our TD3BC+JSRL algorithm can successfully bridge the sim-to-real gap and perform complex control tasks on real hardware. The key achievements include:
- Successful zero-shot transfer from simulation to real Crazyflie quadrotor
- Lower position error than ANNs with explicit action history
- 79% activation sparsity enabling energy-efficient neuromorphic deployment
- Elimination of observation history requirements through temporal processing
- 600-point performance improvement over baseline methods under curriculum learning
These results represent a significant step forward in neuromorphic robotics, demonstrating that spiking neural networks can be effectively trained for real-world control tasks while offering substantial computational and energy efficiency advantages. The successful deployment on physical hardware validates the practical viability of our approach and opens new opportunities for deploying energy-efficient intelligent agents on resource-constrained robotic platforms.
Paper Accepted at NeurIPS 2025
This work has been accepted for presentation at the Conference on Neural Information Processing Systems (NeurIPS) 2025. The complete paper includes additional technical details, ablation studies, and theoretical analysis of the approach.
Series Recap
This concludes our 3-part blog series on Adaptive Surrogate Gradients for Spiking Neural Networks:
- Part 1: Surrogate Gradient Effects - Understanding how surrogate gradient slope settings affect training in deep SNNs
- Part 2: Sequential Reinforcement Learning - Developing the TD3BC+JSRL algorithm for temporal learning
- Part 3: Bridging the Reality Gap - Real-world deployment and evaluation on the Crazyflie quadrotor
Together, these posts provide a comprehensive overview of the challenges and solutions for training and deploying spiking neural networks in real-world robotic control applications.