This work builds upon our comparative study of spiking and non-spiking neural networks in actor-critic reinforcement learning, extending the research to real-world control applications. While the initial study focused on the CartPole task to establish fundamental principles, this follow-up work demonstrates the practical application of spiking neural networks for autonomous drone landing control.
Building on the A2C Comparative Study
Our previous work established key insights about training spiking neural networks with the A2C algorithm, including the effectiveness of surrogate gradients, the importance of temporal dynamics, and the potential for aggressive pruning. This research extends those findings to a more complex, real-world control task: autonomous landing of micro aerial vehicles (MAVs).
The key advancements from the comparative study that enabled this work include:
- Sequence-based Training: Leveraging the A2C algorithm's ability to train on full interaction sequences rather than single state-transitions
- Surrogate Gradient Methods: Using backpropagation through time with surrogate gradients to train spiking networks effectively
- Temporal Dynamics: Understanding how leaky integrate-and-fire neurons can learn temporal relationships
- Pruning Strategies: Applying the aggressive pruning techniques developed in the comparative study
Project Overview: Drone Landing Control
The primary objective was to develop a complete pipeline for training SNN-based controllers that could successfully land a MAV using only sonar altitude readings. This required addressing several key challenges that go beyond the simpler CartPole task:
- Temporal Information Processing: SNNs operate on spike sequences over time, necessitating adaptations to conventional transition-based RL algorithms
- Velocity Estimation: The network needed to learn internal representations of velocity from altitude sequences
- Real-world Deployment: The controller had to generalize from simulation to physical hardware
- Safety Constraints: Ensuring safe landing velocities while maintaining efficiency
Technical Implementation
The project employed an actor-critic training pipeline with several key components:
Network Architecture
The controller architecture consisted of 2 hidden layers, each with 32 leaky integrate-and-fire (LIF) neurons, connected with linear feedforward layers. The input (sonar altitude) was passed directly to the first layer without encoding, as an input current, while the output was discretized to 7 neurons corresponding to acceleration commands. A softmax function was applied to membrane potentials for action selection.
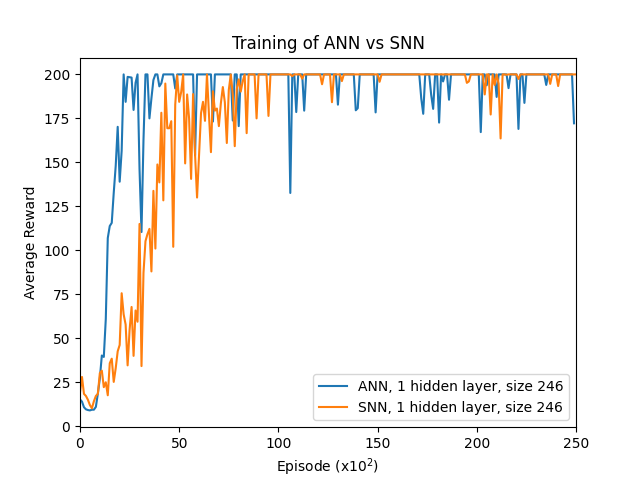
Figure 1: Training performance comparison between SNN and ANN architectures. The SNN shows different convergence characteristics due to its spiking nature and temporal dynamics.
Pre-training Strategy
A critical insight was the necessity of supervised pre-training to help the SNN develop meaningful internal representations. Without proper guidance, the network struggled to learn velocity representations crucial for safe landings. The pre-training task involved learning velocity from sonar readings, which significantly improved training efficiency and reduced computational requirements by an order of magnitude.

Figure 2: Training performance comparison across different model configurations, showing the impact of pre-training and network architecture choices.
Reinforcement Learning Algorithms
Two spiking reinforcement learning algorithms were implemented and compared:
- Spiking A2C (Advantage Actor-Critic): Adapted for the spiking domain, avoiding the shuffling and batching of interactions
- Spiking DQN: Modified to learn from interaction sequences instead of single state-transitions
The A2C approach proved significantly more effective than value function methods, confirming findings from previous research on temporal information processing in reinforcement learning.
Simulation and Training Environment
A lightweight simulator was constructed with second-order dynamics described by:
ḣ(t) = ḣ(t-1) + ḧ(t) · Δt
h(t) = h(t-1) + ḣ(t) · Δt
Where h represents altitude, ḣ is vertical velocity, and ḧ is vertical acceleration after low-pass filtering. The simulator varied starting altitude and velocity across episodes to enhance controller robustness.
Results and Performance
The trained SNN controller demonstrated impressive generalization capabilities across three environments:
Basic Simulation Performance
In the simple simulator, the network exhibited intelligent landing behavior. When starting with non-zero velocity, it promptly issued positive thrust commands to reduce downward velocity, progressively increasing thrust as the MAV approached the ground. This demonstrated the network's ability to modulate thrust based on proximity to the landing surface and its internal velocity representation.
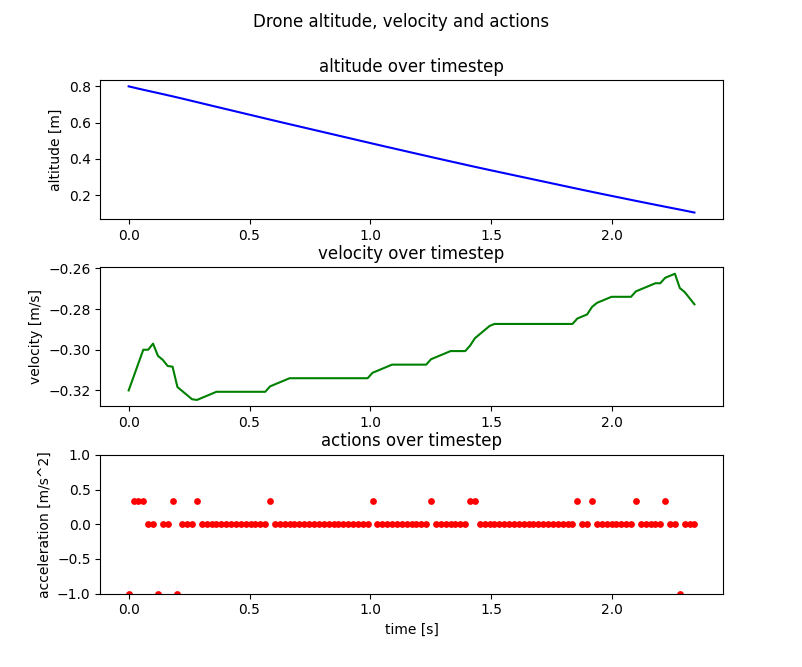
Figure 3: Performance of the SNN-based controller in the basic simulation model. The controller shows intelligent landing behavior with appropriate thrust modulation.
PaparazziUAV Integration
The controller was successfully integrated into the PaparazziUAV framework, with acceleration commands mapped to throttle settings for the Parrot Bebop 2 MAV. The model was converted to C code and wrapped in a PaparazziUAV-compatible module, enabling deployment on real hardware.
Real-world Deployment
Most significantly, the same network deployed on a physical MAV achieved successful landings without additional tuning or training. While slight instabilities occurred that weren't present in simulation (likely due to imperfect tuning of underlying stabilization controllers), the controller demonstrated robust real-world performance.

Figure 4: The SNN controller successfully deployed on a physical Parrot Bebop 2 MAV, demonstrating real-world landing capabilities.
ICNCE 2024 Conference Presentation
This work was presented at the International Conference on Neuromorphic Computing and Engineering (ICNCE) 2024 in Aachen, Germany. The conference presentation highlighted the novel contributions in on-policy reinforcement learning for spiking neural networks and the successful real-world deployment of neuromorphic controllers.
The poster presentation emphasized several key aspects of the research:
NeuroBench Benchmarking Results
Using the NeuroBench framework, we demonstrated the computational efficiency advantages of spiking neural networks:
- Activation Sparsity: SNNs achieved 68-92% activation sparsity compared to 0% for ANNs
- Synaptic Operations: SNNs require only accumulates (ACs) rather than multiply-accumulates (MACs) after spiking layers
- Pruning Effectiveness: SNNs could be pruned by 90%+ without significant performance degradation
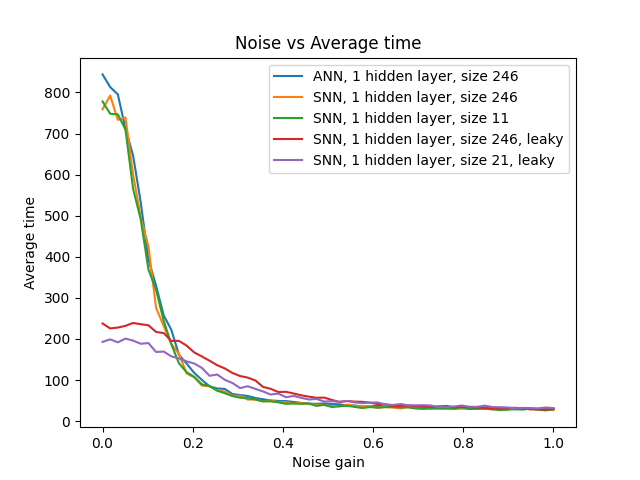
Figure 5: Noise robustness analysis showing SNNs with temporal dynamics outperform traditional ANNs under noisy conditions.
Noise Robustness Analysis
The conference presentation highlighted the superior noise robustness of spiking neural networks, particularly those with temporal dynamics (leaky neurons). At noise levels above 0.15, the leaky SNN models outperformed their non-leaky counterparts, and at noise levels above 0.04, they surpassed ANN performance.
Key Findings and Challenges
The research revealed several important insights:
- Pre-training Necessity: SNNs required supervised pre-training to develop velocity representations
- Training Efficiency: SNN training was significantly slower than comparable artificial neural networks
- Neuron Efficiency: The trained SNN exhibited numerous dead and saturated neurons, indicating training inefficiency
- Action Discretization: The discrete output actions were suboptimal for precise control tasks
- Real-world Generalization: The same network successfully deployed on physical hardware without additional tuning
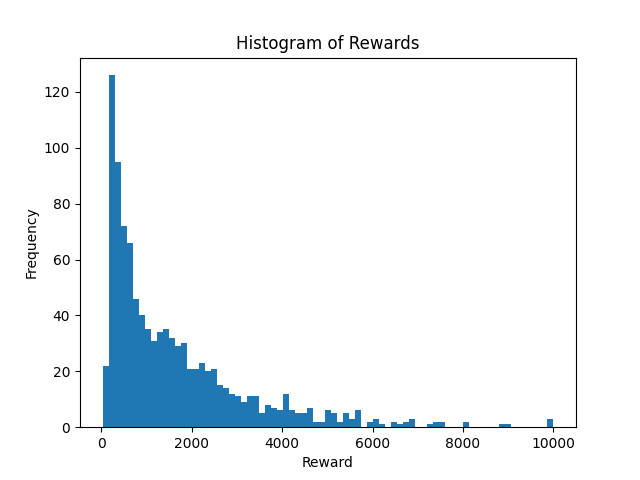
Figure 6: Distribution of neuron activity in the trained SNN, showing the challenge of dead and saturated neurons that limit training efficiency.
Future Research Directions
Several promising avenues for future work have been identified:
- Recurrent Replay Buffers: Investigating R2D2 findings for off-policy, policy gradient algorithms
- Asymmetric Actor-Critic: Combining SNN actors with ANN critics for faster, more stable training
- Stochastic Neuron Models: Exploring models that become more deterministic during training
- Inherent Exploration: Encoding exploration-exploitation balance directly in SNN agents
- Continuous Action Spaces: Developing methods for continuous control outputs rather than discrete actions
Impact and Significance
This work represents a significant step forward in neuromorphic control systems, demonstrating that SNNs can be effectively trained for real-world robotics applications. The successful deployment on physical hardware validates the potential of neuromorphic computing for autonomous systems, while the identified challenges provide clear directions for future research.
The project contributes to the growing body of work on neuromorphic MAV control, building upon previous research in event-driven control and energy-efficient autonomous systems. The findings have implications for the development of next-generation autonomous vehicles and robotics systems that require both computational efficiency and real-time performance.
The conference presentation at ICNCE 2024 helped disseminate these findings to the broader neuromorphic computing community, fostering collaboration and advancing the field toward practical applications of spiking neural networks in autonomous systems.
Code and Resources
The implementation and training code for this project is available on GitHub: https://github.com/korneelf1/SpikingA2C
For more information about the NeuroBench benchmarking framework used in this research, visit: https://neurobench.ai